現在、検証チームの事前準備を、みんなで少しずつ手分けして実施している。
敏腕プログラマの加入により、検証用のサンプル数が10,000件を超えるという、嬉しい悲鳴をあげている。
自動的に取り込めるデータでの検証は問題ないのだが、各自のアイデアに基づく検証は手入力する場面もある。
さすがに10000件手入力は現実的ではないため、サンプリングが必要となる。
サンプリングで重要なことは、母集団の特性をいかに保持したまま少ない件数を抜き出すかだ。
単純なランダムサンプリングの場合、ある少数の集団の特性が失われる可能性があるので注意が必要だ。
今回検証で使う実際のデータで考えてみよう。
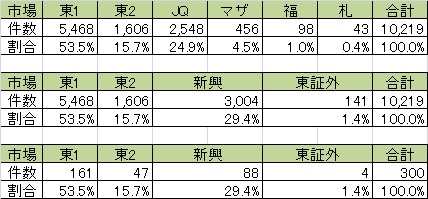
たとえば、市場ごとの件数を見てみる。

表のように、市場ごとにかなりの偏りがあることがわかるだろう。
札幌証券取引所の割合は0.4%であるため、100件しかサンプリングしない場合、0件もありうる。
ここからの進め方は、事前知識とどのような検証を実施するかに依存するが、市場ごとの特性を考慮し、ジャスダックとマザーズを“新興”、福証と札証を“東証外”とまとめてみる。

それでも東証外は少ないので、流動性なども考慮して思い切って除外するか、それとも意外とそこがおいしいかも知れないので、あえて東証外だけ別で検証するなど、キックオフミーティングでの議題としよう。
単純に母集団の特性を保持して300サンプルをサンプリングしたい場合、この市場ごとの割合でランダムに抽出する。

これを「層化抽出法」と呼び、各種マーケティングリサーチや選挙の出口調査で使われる手法だ。
プログラムが苦手な読者は、非定型のIRデータをPDFから抜き出すなど、あえて手作業でしか検証し得ないシステムを目指すのも手だ。
なぜなら、そこはプログラマが面倒くさがってやらない領域なので、エッジが残っている可能性がある。
そんなとき、投下する労力をより効率的なものとするために「層化抽出法」を使ってみるといいだろう。
ちょっとしたことだが、そのわずかな優位性の積み重ねこそが後の巨万の富の種。
ゆめゆめおろかにしないよう。




